


In this tutorial, we will be training a custom detector for mask detection using YOLOv5 PyTorch implementations
HOW TO BEGIN?
- First, ✅Subscribe to my YouTube channel ???????? https://www.youtube.com/c/techzizou ????????
- Open my Colab notebook on your browser.
- Click on File in the menu bar and click on Save a copy in drive. This will open a copy of my Colab notebook on your browser which you can now use.
- Next, once you have opened the copy of my notebook and are connected to the Google Colab VM, click on Runtime in the menu bar and click on Change runtime type. Select GPU and click on save.
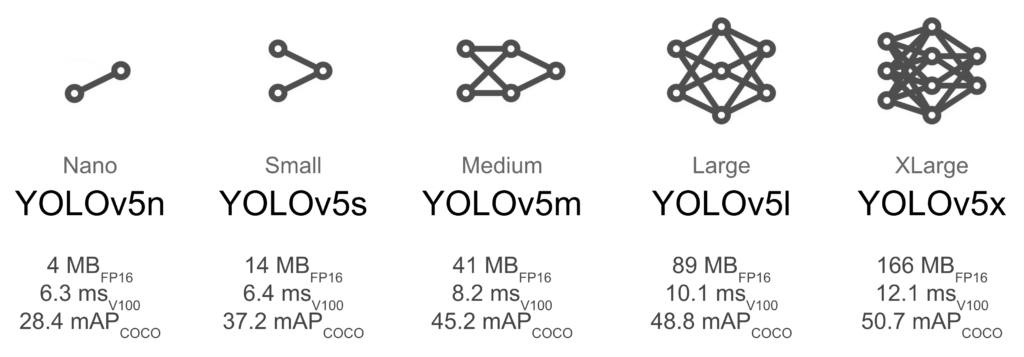
Use any one of the following models:
In this tutorial, we will be using the small yolov5 i.e. YOLOv5s

Follow these 7 steps to train your custom YOLOv5 object detector:
- 1) Mount the drive
- 2) Clone the
yolov5official git repository - 3) Navigate to the yolov5 folder, Install PyTorch and all the required libraries and dependencies
- 4) Create & upload the necessary files we need for training a custom detector
- 5) Load Tensorboard to visualize training metrics
- 6) Train the Model
- 7) Test the trained model
NOTE: If you get disconnected or lose your session for some reason you have to run steps 1,3 and 5 again.
1) Mount the drive
#mount drive
%cd ..
from google.colab import drive
drive.mount('/content/gdrive')
# this creates a symbolic link so that now the path /content/gdrive/My\ Drive/ is equal to /mydrive
!ln -s /content/gdrive/My\ Drive/ /mydrive
# list the contents of /mydrive
!ls /mydrive
2) Clone the yolov5 official git repository
!git clone https://github.com/ultralytics/yolov5.git
3) Navigate to the yolov5 folder, Install PyTorch and all the required libraries and dependencies
#Navigate to /mydrive/yolov5
%cd /mydrive/yolov5
!pip install -r requirements.txt
#Check if pytorch installed
import torch
import os
from IPython.display import Image, clear_output # to display images
print(f"Setup complete. Using torch {torch.__version__} ({torch.cuda.get_device_properties(0).name if torch.cuda.is_available() else 'CPU'})")
4) Create & upload the following files which we need for training a custom detector
a. Labeled Custom Dataset
b. process_yolov5.py file (to split dataset into train-val folders for training)
c. data.yaml file
d. config file (custom_yolov5s.yaml)
CHANGE I have uploaded my custom files on GitHub. I am working with 2 classes i.e. with_mask and without_mask
4(a) Upload the Labeled custom dataset obj.zip file to the yolov5 folder on your drive and unzip it
Create the zip file obj.zip from the obj folder containing both the folders’ images and labels. The images folder has all the input images “.jpg” files and the labels folder has their corresponding YOLO format labeled “.txt” files.
Upload the zip file to the yolov5 folder on your drive.
Labeling your Dataset
Input image example (Image1.jpg)


You can use any software for labeling like the labelImg tool.

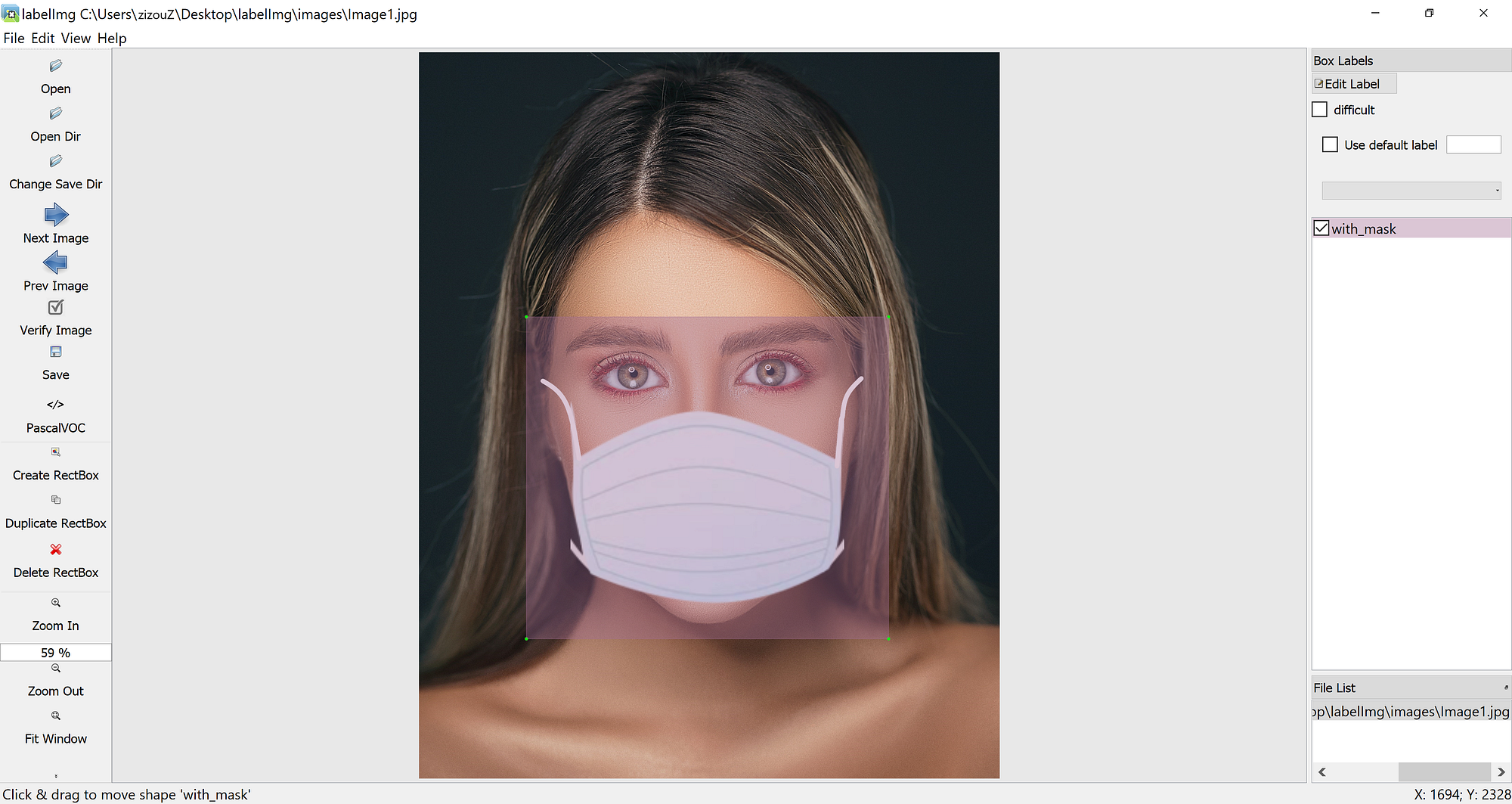
Click on the link below to know more about the labeling process and other software for it:
NOTE: Garbage In = Garbage Out. Choosing and labeling images is the most important part. Try to find good-quality images. The quality of the data goes a long way towards determining the quality of the result.
The output YOLO format TXT label file looks as shown below.


Unzip the obj.zip dataset and its contents
!unzip -q /mydrive/yolov5/obj.zip -d /mydrive/yolov5
Note: You can also use other methods to get your dataset like the curl command to download the dataset from Roboflow. Visit Roboflow and go to the Public Datasets tab for more datasets.
curl -L "https://public.roboflow.ai/ds/YOUR-API-KEY-HERE" > roboflow.zip; unzip roboflow.zip; rm roboflow.zip
*Since I already have a simple dataset archive ready I will be using that.
4(b) Split the dataset images and labels into train-val. Run the “process_yolov5.py” python script to create the train & val folders inside the yolov5/obj directory
Here the train folder will have 80% of the dataset images and their labels while the val folder will have 20% of the dataset images and their labels. The test images folder is optional(read here on YOLOv5 GitHub page)
The split folders will be in the following order:

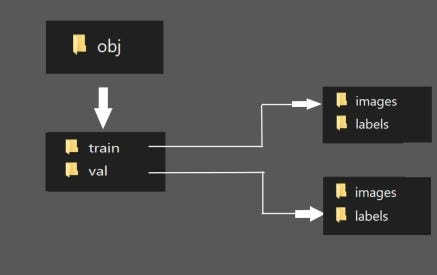
Run the process script
# run process_yolov5.py (this creates the train and val folders containing the images and labels folder) !python process_yolov5.py # list the contents of obj folder to check if the train and val folders have been created !ls obj
4(c) Create your data.yaml file and upload it to the yolov5 folder in your drive
This file contains the path to your train and test images. We created these 2 text folders in the previous step.
This file also contains the number of classes (nc) and their names.
data.yaml file is shown below:
# train and val data as 1) directory: path/images/, 2) file: path/images.txt, or 3) list: [path1/images/, path2/images/] train: /mydrive/yolov5/obj/train/images/ val: /mydrive/yolov5/obj/val/images/ #test: optional nc: 2 names: ['with_mask', 'without_mask']
4(d) Set the config file
(Define YOLOv5 Model Configuration and Architecture)
Next, we write a model configuration file for our custom object detector. For this tutorial, we will be using YOLOv5s. You have the option to pick from all the YOLOv5 models mentioned below:
- YOLOv5s
- YOLOv5m
- YOLOv5l
- YOLOv5x
- YOLOv5n
You will find these inside the models’ subfolder. You can also edit the structure of the network in this step, though rarely will you need to do this. Here is the YOLOv5s model configuration file.
The default yolov5s.yaml config file is shown below:
# YOLOv5 ???? by Ultralytics, GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
Copy the yaml file above to the yolov5 root folder, rename it to custom_yolov5s.yaml and lastly change the number of classes(nc) in the custom_yolov5s.yaml file
- Set the names of the files below according to the model you are using. I am using YOLOv5s so I’m using the filenames with yolov5s
- Change the number of classes (nc) to what you have.
#Copy the yolov5s.yaml config file to your drive inside the yolov5 folder !cp models/yolov5s.yaml /mydrive/yolov5/ #Rename the yolov5s.yaml file to custom_yolov5s.yaml !mv yolov5s.yaml custom_yolov5s.yaml #Change number of classes in the custom_yolov5s.yaml !sed -i 's/nc: 80/nc: 2/' custom_yolov5s.yaml
5) Load Tensorboard to visualize training metrics
#@title Select YOLOv5 ???? logger {run: 'auto'}
logger = 'TensorBoard' #@param ['ClearML', 'Comet', 'TensorBoard']
if logger == 'ClearML':
%pip install -q clearml
import clearml; clearml.browser_login()
elif logger == 'Comet':
%pip install -q comet_ml
import comet_ml; comet_ml.init()
elif logger == 'TensorBoard':
%load_ext tensorboard
%tensorboard --logdir runs/train
6) Train the model
We can pass the following arguments in the training command:-
- img: define input image size. The default is 640. See this table for more info
- batch: determine batch size
- epochs: define the number of training epochs.
- data: set the path to our yaml file (data.yaml file)
- cfg: specify our model configuration
- nosave: only save the final checkpoint
- cache: cache images for faster training
- name: result names
- weights: specify the weights. You can use the pre-trained weights of whichever model you want to train here.
- yolov5n.pt
- yolov5s.pt
- yolov5m.pt
- yolov5l.pt
- yolov5x.pt
The YOLOv5 framework automatically downloads the weights specified here in this command.
!python train.py --img 640 --batch 8 --epochs 50 --data data.yaml --cfg custom_yolov5s.yaml --weights yolov5s.pt
#Train command with nosave & cache parameters for faster training
#!python train.py --img 640 --batch 8 --epochs 50 --data data.yaml --cfg custom_yolov5.yaml --weights yolov5.pt --nosave --cache
Retraining from the last saved checkpoint
!python train.py --resume --weights runs/train/exp/weights/last.pt --data data.yaml --cfg custom_yolov5s.yaml --epochs 50 --img 640
7) Test the trained model
!python val.py --weights /mydrive/yolov5/runs/train/exp/weights/best.pt --data data.yaml --img 640
DETECTION ON IMAGES
Run Detector
!python detect.py --source /mydrive/mask_test_images --weights /mydrive/yolov5/runs/train/exp/weights/best.pt --img 640 --conf 0.2 --save-txt --save-conf
Display the image outputs
#display inference on ALL test images
import glob
from IPython.display import Image, display
for imageName in glob.glob('/mydrive/yolov5/runs/detect/exp/*.jpg'): #assuming JPG
display(Image(filename=imageName))
print("\n")
DETECTION ON VIDEOS
Run Detector
!python detect.py --source /mydrive/mask_test_videos/test.mp4 --weights /mydrive/yolov5/runs/train/exp/weights/best.pt --img 640 --conf 0.2 --save-txt --save-conf
# 0 # webcam
# img.jpg # image
# vid.mp4 # video
# path/ # directory
# path/*.jpg # glob
# 'https://youtu.be/Zgi9g1ksQHc' # YouTube
# 'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream
(OPTIONAL STEP) CONVERSION
CONVERT TO TFLITE, ONNX, TORCHSCRIPT, AND TENSORFLOW MODEL
(Using the export.py file in YOLOv5’s repository here)
Export a YOLOv5 PyTorch model to other formats. TensorFlow exports authored by https://github.com/zldrobit
Format | `export.py --include` | Model
--- | --- | ---
PyTorch | - | yolov5s.pt
TorchScript | `torchscript` | yolov5s.torchscript
ONNX | `onnx` | yolov5s.onnx
OpenVINO | `openvino` | yolov5s_openvino_model/
TensorRT | `engine` | yolov5s.engine
CoreML | `coreml` | yolov5s.mlmodel
TensorFlow SavedModel | `saved_model` | yolov5s_saved_model/
TensorFlow GraphDef | `pb` | yolov5s.pb
TensorFlow Lite | `tflite` | yolov5s.tflite
TensorFlow Edge TPU | `edgetpu` | yolov5s_edgetpu.tflite
TensorFlow.js | `tfjs` | yolov5s_web_model/
PaddlePaddle | `paddle` | yolov5s_paddle_model/
Requirements:
$ pip install -r requirements.txt coremltools onnx onnx-simplifier onnxruntime openvino-dev tensorflow-cpu # CPU
$ pip install -r requirements.txt coremltools onnx onnx-simplifier onnxruntime-gpu openvino-dev tensorflow # GPU
Usage:
$ python export.py --weights yolov5s.pt --include torchscript onnx openvino engine coreml tflite ...
Convert using the export.py script inside the yolov5 root directory (Read more about exporting models here)
#TFLITE FP16 !python export.py --weights /mydrive/yolov5/runs/train/exp/weights/best.pt --img 640 --data data.yaml --include tflite #TFLITE INT8 #!python export.py --weights /mydrive/yolov5/runs/train/exp/weights/best.pt --img 640 --data data.yaml --include tflite --int8 # ONNX & TORCHSCRIPT #!python export.py --weights /mydrive/yolov5/runs/train/exp/weights/best.pt --data data.yaml --include torchscript onnx #TensorFlow GraphDef & Tesnorflow SavedModel format #!python export.py --weights /mydrive/yolov5/runs/train/exp/weights/best.pt --img 640 --data data.yaml --include pb saved_model # TensorRT (TensorRT has to be converted on the same GPU it will be inferenced on) #!python export.py --weights /mydrive/yolov5/runs/train/exp/weights/best.pt --data data.yaml --include engine
Detect using the detect.py script inside the yolov5 root directory
#TFLITE FP16 !python detect.py — weights /content/gdrive/MyDrive/yolov5/runs/train/exp/weights/best-fp16.tflite — data data.yaml — source /mydrive/images/image3.jpg #TFLITE INT8 #!python detect.py --weights /content/gdrive/MyDrive/yolov5/runs/train/exp/weights/best-int8.tflite --data data.yaml --source /mydrive/images/image3.jpg #ONNX #!python detect.py --weights /content/gdrive/MyDrive/yolov5/runs/train/exp/weights/best.onnx --data data.yaml --source /mydrive/images/image3.jpg #Torchscript #!python detect.py --weights /content/gdrive/MyDrive/yolov5/runs/train/exp/weights/best.torchscript --data data.yaml --source /mydrive/images/image3.jpg #TensorRT #!python detect.py --weights /content/gdrive/MyDrive/yolov5/runs/train/exp/weights/best.engine --data data.yaml --source /mydrive/mask_test_images/image3.jpg
Display the image outputs
#display inference on ALL test images
import glob
from IPython.display import Image, display
for imageName in glob.glob('/mydrive/yolov5/runs/detect/exp/*.jpg'): #assuming JPG
display(Image(filename=imageName))
print("\n")
That’s it for YOLOv5! ????
References
https://github.com/ultralytics/yolov5
https://blog.roboflow.com/how-to-train-yolov5-on-a-custom-dataset/
https://github.com/ultralytics/yolov5/wiki/Train-Custom-Data
https://github.com/ultralytics/yolov5/releases