


In Machine Learning, data labeling is the process of identifying raw data (images, text files, videos, etc.) and adding one or more meaningful and informative labels to provide context so that a machine learning model can learn from it. For example, labels might indicate whether a photo contains a bird or car, which words were uttered in an audio recording, or if an x-ray contains a tumor. Data labeling is required for a variety of use cases including computer vision, natural language processing, and speech recognition.
When building a computer vision system, you first need to label images, pixels, or key points, or create a border that fully encloses a digital image, known as a bounding box, to generate your training dataset. For example, you can classify images by quality type (like product vs. lifestyle images) or content (what’s actually in the image itself), or you can segment an image at the pixel level. You can then use this training data to build a computer vision model that can be used to automatically categorize images, detect the location of objects, identify key points in an image, or segment an image.


Image Dataset labeling is probably the most tedious part of the entire process of training a Machine Learning model. Collecting images for our dataset, and then annotating each image can seem like a daunting task. Thankfully, we now have many software tools that enable us to carry out this task with ease and save a lot of time and effort.
Data annotation generally refers to the process of labeling data. Data annotation and data labeling are often used interchangeably, although they can be used differently based on the industry or use case.
Labeled data highlights data features or properties, characteristics, or classifications that can be analyzed for patterns that help predict the target. For example, in computer vision for autonomous vehicles, a data labeler can use frame-by-frame video labeling tools to indicate the location of street signs, pedestrians, or other vehicles.
There are many types of annotation techniques like bounding boxes, semantic segmentation, landmarks, polygons, cuboids, and polylines.
In this article, I will be explaining the process of image annotation using bounding boxes to get you started with the process of training a Machine Learning model.
LABELING PROCESS
To demonstrate the image labeling process, I will use a labeling tool called OpenLabeling which is run as a python script from the location containing the input images directory and a text file with the names of all the required classes written in it. We can use this tool to label objects in images as well as in videos.
Here I will be explaining the labeling process for both images and videos. This will give you a better understanding of the basics of labeling any dataset.
The contents of this tutorial are as follows:
A) Labeling Images using OpenLabeling tool's main.py script.
B) Labeling Videos using OpenLabeling tool's main.py script.
C) Auto-Labeling images or videos using a pre-trained model's frozen inference graph in main_auto.py script.
D) Other labeling tools and dataset sources.Before we begin labeling, go to the OpenLabeling tool’s Github here and download the zip file for it and unzip it. Navigate to the OpenLabeling-master folder.


As you can see on the OpenLabeling tool’s Github page here, we need these four modules in the “requirements.txt” file to be installed on our system.


Run either of the commands below from the folder containing the requirements.txt file as shown in the pic below. This will automatically install all these 4 modules which are needed to run the main_auto.py script. The main.py script needs only NumPy to be installed.
python -mpip install -U -r requirements.txtOR
pip install -r requirements.txt

** If you don’t have pip go to the pip documentation site here for instructions on how to install it.

SECTION (A)
LABELING IMAGES
Follow these 5 steps for labeling objects in images.
STEP (1)
Navigate to the main folder. Empty the contents in the input folder and class_list.txt. The contents of the main folder should look like as shown below.


STEP (2)
Open class_list.txt and write the names of your classes. (One in each line without any space between words of a class eg: vehicle_license_plate). I am working with 2 classes (viz. “with_mask” and “without_mask”).


STEP (3)
Put all your images in the input folder
NOTE : Garbage In = Garbage Out. Choosing and labeling images is the most important part. Try to find good quality images. The quality of the data goes a long way towards determining the quality of the result.
STEP (4)
Open a command prompt and navigate to the current directory inside OpenLabeling tool’s main folder which contains the class_list.txt file, your input images folder, and the main.py script.
Next, run the main.py script. This creates the YOLO_darknet and PASCAL_VOC folders inside the output folder which contain the “.txt” and “.xml” files of the same name as the input images. These “.txt” and “.xml” files are empty. They will save label data in them once you have labeled the images.


This creates the output folder as shown below:


The contents of the output folder look like as shown below.



Let’s see an example of an input image ( Image1.jpg )


Once you’ve run the main.py python script from the location containing the input images folder and the classes file as mentioned in the steps above, you will see the OpenLabeling tool GUI as shown below.


STEP (5)
Label the image by drawing the bounding box for the object.


Now that we have labeled the image, the output YOLO_darknet and PASCAL_VOC files will now save label data in them. The outputs for them look like as shown below:
YOLO format labeled text file


As you can see, the YOLO label file contains 5 values. The 1st value is that of the class index id as it was mentioned in the class_list.txt file.
The index starts at 0(zero). So 0 value here means it is the very first class i.e. “with_mask”. The remaining 4 values in the file are object coordinates and the height and width of the bounding box.
The label file will contain normalized values for all 5 parameters so their values will be between 0 to 1. The label for one object looks like as shown below.
<object-class> <x_center> <y_center> <width> <height>
Where:
<object-class>– integer number for an object from0to(classes-1)<x_center> <y_center> <width> <height>– float values relative to width and height of the image, will be between 0.0 to 1.0- for example:
<x> = <absolute_x> / <image_width>or<height> = <absolute_height> / <image_height> - attention:
<x_center> <y_center>– are the center of the rectangle (not top-left corner)
PASCAL_VOC format labeled XML file


The PASCAL_VOC XML file contains the values as shown in this pic. It contains the values of the 4 coordinates of the bounding box mentioned here as xmin, ymin, xmax, ymax. (xmin-top left, ymin-top left, xmax-bottom right, ymax-bottom right)
It also contains the name of the input image file and the name of the object class in the image. If the image contains multiple object classes, the XML file will also have multiple classes and multiple values for their respective coordinates written in them.
See the example for an image with multiple classes below.
Image2.jpg


Note: Use A & D on your keyboard to toggle between images. Use W & S on your keyboard to toggle between classes.




The output YOLO_darknet and PASCAL_VOC label files for the above labeled image look like as shown below:
YOLO format labeled text file


The YOLO format label file contains multiple object labels, each in a new line. All the values represent the same parameters as mentioned earlier.
PASCAL_VOC format labeled XML file


The PASCAL_VOC label file also contains multiple object classes and different coordinates for each of those object classes. All the values represent the same parameters as mentioned earlier.
NOTE: Do not change the names of the input image files after running the main.py script as the XML files created will have the names of the image files from the input folder written in them along with the annotations and the class names. If you have to change the name of your input images for some reason, do so prior to running the main.py script.
SECTION (B)
LABELING VIDEOS
Follow these 5 steps for labeling objects in a video.
STEP (1)
Navigate to the main folder. Empty the contents in the input folder and class_list.txt.
STEP (2)
Open class_list.txt and write the names of your classes. (One in each line without any space between words of a class eg: vehicle_license_plate). I am working with 2 classes (viz. “with_mask” and “without_mask”)

STEP (3)
Put your video in the input folder. You can also put multiple videos inside the input folder at once. My video is named “mask.mp4“.
mask stock video from pexels.com
NOTE : Garbage In = Garbage Out. Choosing and labeling images is the most important part. Try to find a good quality video. The quality of the data goes a long way towards determining the quality of the result.
STEP (4)
Open a command prompt and navigate to the current directory inside OpenLabeling tool’s main folder which contains the class_list.txt file, your input folder, and the main.py script.

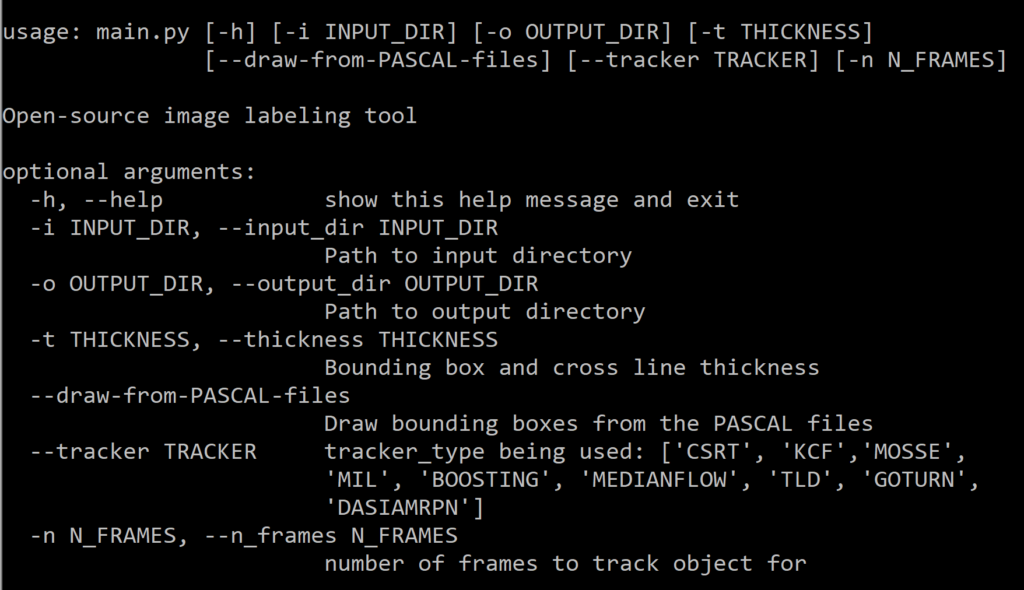
Next, run the main.py script using the following command:
python main.py -t 2 -i input -o output --tracker KCF -n 50where t is the thickness of the bounding box, KCF is the type of tracker, and n is the number of frames you want to auto label at a time.
You don’t have to mention input and output paths everytime. It takes default values of these which are input and outputfolders in themaindirectory.
The default value for the thickness of the bounding box is 2.
I have used the KCF tracker. DASIAMRPN tracker is the best but it needs other modules like PyTorch to be installed. To install DASIAMRPN tracker click this link to jump to that section on OpenLabeling’s GitHub page.


The main.py script creates the output folder.
The script first converts the video into individual frames as shown in the image below. As you can see the video has been converted into 605 frames.

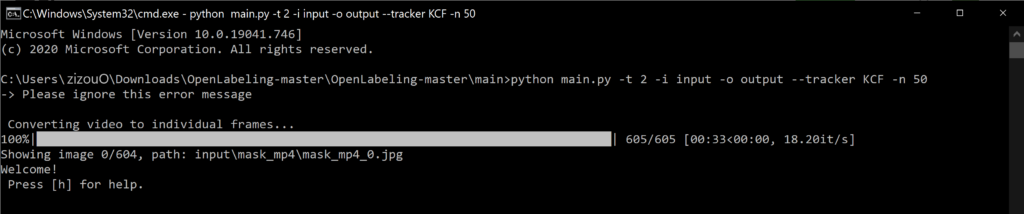
This creates a folder inside the input folder with the same name as the video.


This mask_mp4 folder contains all the 605 frame images that were just created with the name of the video followed by its frame number. So for our video “mask.mp4” the first image is mask_mp4_0.jpg and the last one is mask_mp4_604.jpg

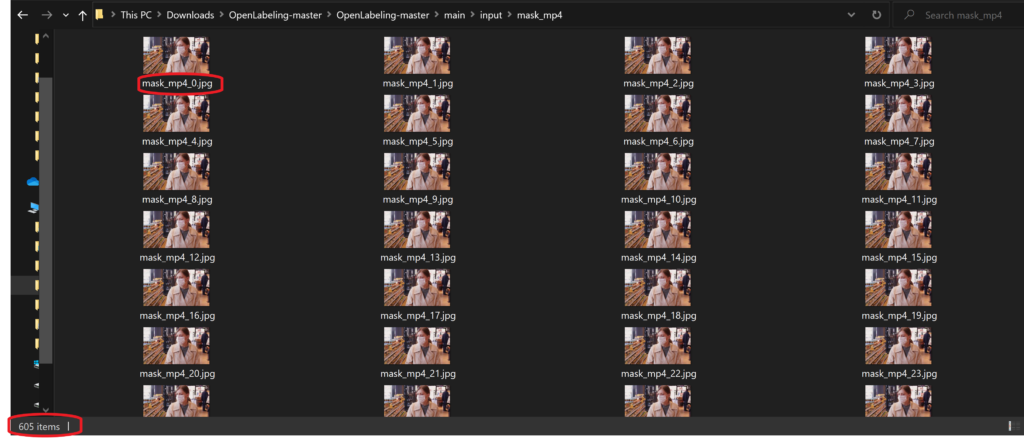


The script also creates the YOLO_darknet, PASCAL_VOC, and .tracker folders inside the output folder which contain the “.txt” and “.xml” files of the same name as the video image files that were created. These “.txt” and “.xml” files are empty. They will save label data in them once you have labeled the images.
The contents of the output folder look like as shown below:

PASCAL_VOC and YOLO_darknet files created after running the main.py script shown below.


The OpenLabeling GUI looks like as shown below.


STEP (5)
Label the object in the first frame and press P on your keyboard.


After labeling the object and pressing P, the script runs the tracker using the object in the image we labeled and then auto-labels the next 50 frames based on the object in the first frame. It auto-labels 50 frames since we gave the number of frames (n)as50 in our command. You can set it to whatever you want depending on the total number of frames in one video. If you are putting multiple videos in the input folder where the object in each video might be at different locations, the auto labeling will stop after the last frame of a particular video. So from the next frame which will be the first frame of the next video, you will have to perform the same auto-labeling process for it again.


You can manually check all the auto-labeled images later to look for any mislabeled or unlabeled images.
NOTE: Do not change the names of the input video or its image files that were created after running the main.py script as the XML files created will have the names of the video image files from the input folder written in them along with the annotations and the class names. If you have to change the name of your input video frame images for some reason, do so prior to running the main.py script.
SECTION (C)
Auto-Labeling images or videos using a pre-trained model’s frozen inference graph in main_auto.py script
The main_auto.py script lets you auto-label objects if you already have a frozen inference graph of a trained model. Let’s say you have 10,000 images for an object. You labeled 2000 of those images for an object and then used those labels to train a deep learning object detection model.
Now, you can use the inference graph that is created while training such a model here in the main_auto.py script to auto label the rest of the 8000 unlabeled images. The main_auto.py script basically uses the inference graph to run object detection on those 8000 images and labels the objects in those images automatically.
I trained an object detector model for people wearing masks using TensorFlow. The pre-trained model I used was ssd_mobilenet_v2_coco. I alsocreated a frozen inference graph during training which I will use to auto-label a completely new mask dataset. Follow the steps below.
STEP (1) Install TensorFlow
First, we need to have TensorFlow installed on our system. If you have pip, run pip install tensorflow in the command prompt to install TensorFlow.
The tf_object_detection module in the main_auto.py script only works for TensorFlow 1.x. For TensorFlow 2.x, you will have to make a few changes which I have explained later.
STEP (2) Make changes to the code
In the main_auto.py script make the following changes:
Line 29 (if you are on Windows)
#from
sys.path.insert(0,"..")
#to
sys.path.insert(0,"../object_detection")Line 30
#from
from object_detection.tf_object_detection import ObjectDetector
#to
from tf_object_detection import ObjectDetectorLine 47
#from
graph_model_path = "../object_detection/models/ssdlite_mobilenet_v2_coco_2018_05_09/frozen_inference_graph.pb"
#to the path of your frozen infererence graph
graph_model_path = "frozen_inference_graph.pb"I have put the frozen inference graph of my custom trained model in the main folder alongside main.py and main_auto.py .
If you are labeling one of the object classes in the pre-trained model(coco has 80 classes), you can simply download the pre-trained model, put it inside a folder named models inside the object_detection folder, and give its frozen inference graph’s path in the graph_model_path line. (See this section on OpenLabeling’s Github for more info on this). But, since I am labeling a custom object (i.e. mask), I will be using my custom trained model’s frozen inference graph.
Line 327
#from
new_path = img_path.replace(INPUT_DIR, new_path, 1)
#to
new_path = os.path.join(new_path,os.path.basename(os.path.normpath(img_path)))Make the above change so that the labeled text and XML files are written inside the YOLO_darknet & PASCAL_VOC folders. So if you want to view and edit your new auto-labeled dataset, just run the main.py script.
NOTE: One important thing is that the tf_object_detection.py script which we are importing in our main_auto.py script works for Tensorflow 1.x only, i.e. it is not compatible with TensorFlow version 2 and above. Since most people now use TF 2.x it is advisable to update your code in the tf_object detection.py script.


For Tensorflow 2.0 and above, open the tf_object_detection.py script in the object_detection folder inside the Openlabeling_master folder and make the following changes.
Make the next changes only for TensorFlow 2.x . If you have TensorFlow 1.x you can skip these.
Line 9
#from
tf.Session
#to
tf.compat.v1.SessionLine 16
#from
tf.GraphDef()
#to
tf.compat.v1.GraphDef()Line 18
#from
tf.gfile.GFile
#to
tf.compat.v2.io.gfile.GFileLine 25, 33 and 34
#from
tf.get_default_graph()
#to
tf.compat.v1.get_default_graph()NOTE: I have uploaded my updated main_auto.py and tf_object_detection.py scripts which are compatible with TensorFlow 2 on this link inside the update folder.
STEP (3) Edit the “class_list.txt” file
Open the class_list.txt file and write the names of the classes in the same order id number as you did in the label_map.pbtxt file while training the deep learning model.
NOTE: Label map id 0 is reserved for the background label. So you can write the first line which is index id 0 in the class_list.txt as “unused”. I labeled my 1370 images dataset with class_list.txt as shown below:


STEP (4) Edit the “config.ini” file
Open config.ini file and change the OBJECT_SCORE_THRESHOLD to whatever minimum accuracy you need for object detection.
Also, change CUDA_VISIBLE_DEVICES=’’ to CUDA_VISIBLE_DEVICES=0 if you have CUDA and CUDNN installed and configured on your system with a CUDA capable GPU device. Using a GPU will obviously speed up the object detection and labeling process. If you don’t have CUDA on your system, you can still label the images using the main_auto.py script.
STEP (5) Run the “main_auto.py“ script
FOR IMAGES
Example of an input image


Put the images in the input folder and run the following command:
python main_auto.py -i input -o output -t 2
#you dont have to mention input and output paths. It takes default values of these which are input and output folders.
#the dafault value for thickness of the box is 2Once you run the above command, the main_auto.py script will run the tracker, perform object detection on all the new images using the trained model’s inference graph and label the objects in those images automatically.
After the auto-labeling process is over, run the main.py script to view and edit these newly labeled images. Use the following command:
python main.py

You can manually check all the auto-labeled images now to look for any mislabeled or unlabeled images.
FOR VIDEOS
You can use the same method mentioned above to also auto-label objects in a video using your trained model’s frozen inference graph.
Just put the video or videos in the input folder and run the same command as we used for images. It will convert the video into individual frame images first just as explained in Section (B) above. The script then auto-labels them using the inference graph. I used the same video(mask.mp4) as earlier.
Put your video in the input folder. You can also put multiple videos inside the input folder at once. My video is named “mask.mp4“.
mask stock video from pexels.com
Run the main_auto.py script:
python main_auto.py -i input -o output -t 2
#you dont have to mention input and output paths. It takes default values of these which are input and output folders.
#the dafault value for thickness of the box is 2.The main_auto.py script converts the video into 605 individual frame images, runs object detection on them, and then labels them automatically. It took less than 2 minutes to convert the video into 605 frames and auto-label each frame image using my custom trained model’s inference graph.




Again, to view and edit the labels in the new auto-labeled images, run the main.py script:
python main.py

You can manually check all the auto-labeled images now to look for any mislabeled or unlabeled images.
SECTION (D)
Other Labeling Tools and Dataset Sources
You can use other tools for labeling like the labelImg software which is a very popular labeling tool. The GUI for it looks like as shown below.


To know more about the labelImg tool and how to install it, go to its GitHub page.
There are many labeling tools that are out there now which have many more features and a very user-friendly interface.
Check out these links for various labeling tools:
https://github.com/heartexlabs/awesome-data-labeling
http://lionbridge.ai/articles/image-annotation-tools-for-computer-vision/
Dataset Sources
You can download datasets for many objects from the sites mentioned below. These sites also contain images of many classes of objects along with their annotations/labels in multiple formats such as the YOLO_DARKNET text files and the PASCAL_VOC XML files.
On Open Images Dataset by Google, you can download annotations/labels in multiple formats and in various types like detection or segmentation. See pics for detection and segmentation type labeled images for wheels below.




My Files
You can download my edited main_auto.py and tf_object_detection scripts from the link below. These files are compatible with TensorFlow 2 and above.
techzizou/OpenLabelinggithub.com
CREDITS
References
Labeling Tools
OpenLabeling tool by João Cartucho. Check out its GitHub page to know more about its features. Click on the link below:
https://github.com/Cartucho/OpenLabeling
The labelImg tool mentioned here can be found at the link below:
https://github.com/tzutalin/labelImg#labelimg
Mask Dataset Sources
I used these 2 datasets for training a custom deep learning model using MobileNet and then created a frozen_inference_graph from the trained custom model.
More Mask Datasets
- Joseph Nelson Roboflow
- Prasoonkottarathil Kaggle (20000 images)
- Ashishjangra27 Kaggle (12000 images )
- Andrewmvd Kaggle
Video Sources
YouTube videos on this !
Part 1

Part 2

Part 3
